
六和汤(六和汤藿香香薷代用茶)
1、六和汤是出自太平惠民和剂局方的方剂,具有和中祛湿升清降浊的功效,主治心脾不调霍乱转筋呕吐泄泻等多种病症,妇人胎前产后亦可服用,...
扫一扫用手机浏览
强化学习是一种通过智能体与环境交互,依据获得的奖励信号来学习最优策略的机器学习方法,其核心概念包括;强化学习的特征包括试错探索延迟奖励时间关联性重要以及智能体动作影响后续数据采集在强化学习中,保持智能体动作的稳定极为关键,以确保数据质量,从而提升学习效率通过与监督学习的比较,强化学习展现出独特的学习模式和挑战监督学习提供即时反馈,有助于智能体快速学习,而强化学习则需要智能体在不;状态观察与特征提取由于无法知道宇宙所有粒子的所有状态,强化学习通过引入假设来观察世界并得到若干可以用数字表示的信息即特征这些特征被认为是与目标即奖励相关的主要因素有限计算资源由于计算资源和内存有限,强化学习使用函数拟合模型来近似表示状态动作和奖励之间的关系这种拟合不可能是。
与监督学习对比两者均通过交互学习,但监督学习依赖标签数据,而强化学习通过环境反馈奖励信号优化策略与无监督学习对比深度强化学习的神经网络组件可自动提取特征如DQN从像素中学习物体识别,类似无监督学习的特征学习目标,但强化学习额外关注决策优化与其他技术互动传统方法如A*搜索算法可;特点强化学习与无监督学习机制不同,无监督学习目标是挖掘数据的潜在结构,而强化学习是通过与环境交互;环境Environment智能体交互的外部系统,状态随动作变化并反馈强化信号状态State环境在某一时刻的特征表示,决定智能体可采取的动作动作Action智能体在特定状态下执行的行为,影响环境状态和回报强化信号Reward环境对动作的即时反馈,用于评价动作的优劣强化学习的运行机制试探;强化学习的基本要素通常包括状态动作和奖励,部分资料还提及策略价值函数和模型等要素,其中最核心的是状态动作和奖励以下是对这些要素的详细介绍核心三要素 状态State状态用于描述环境的当前情况,是智能体感知到的环境信息它为智能体提供了关于环境的重要线索,帮助智能体了解自身所处的;这种结合深度学习技术的特点,使得TD3算法具备了深度强化学习算法的典型特征,能够有效地解决一些传统强化学习算法难以处理的复杂问题从算法框架角度TD3算法属于ActorCritic框架下的确定性深度强化学习算法在ActorCritic框架中,Actor网络根据当前状态输出确定性的动作,而Critic网络则评估该动作在当前状态下;一对强化学习的界定核心特征强化学习是通过不断试错,无需对环境进行准确建模,以获得累计回报最高策略的方法,涵盖valuebased如DQNpolicybased如PPO及部分modelbased方法争议点蒙特卡洛树搜索MCTS常被归类为modelbased RL,但严格来说其属于启发式搜索算法,与强化学习的核心逻辑。
")
系统达到最优状态该过程体现强化学习的核心特征通过试错积累经验,无需预先标注的训练数据,仅依赖;强化学习的基本组成部分包括智能体环境状态动作奖励策略价值函数和模型,具体介绍如下智能体是强化学习中的决策与学习主体它能够感知环境的状态,并根据自身的策略选择并执行相应的动作智能体通过不断地与环境进行交互,积累经验,从而优化自身的决策能力,以实现长期收益的最大化例如,在;强化学习适合解决序列决策问题,尤其是满足以下核心特征的问题动作能改变环境状态可获得环境反馈奖惩;强化学习是智能体学习如何在环境中采取一系列行为,从而获得最大化的累积回报,其本质是寻找最优决策的过程,核心特征为试错法搜索和延迟奖励强化学习在机器学习中的定位 机器学习主要分为监督学习非监督学习和强化学习三类监督学习样本有正确标签,如房价预测中给出房子实际卖价,可解决回归和分类问题。
基本概念强化学习属于机器学习领域,用于解决序贯决策任务与预测任务不同,决策任务中每个选择会带来“;它研究智能体Agent如何在与环境的交互中学习策略,以最大化某种累积奖励以下是对强化学习的详细;强化学习模型结构围绕智能体环境交互框架设计,通常包含策略网络决定动作选择和价值网络评估状态价值,但不限定具体网络类型例如,深度Q网络DQN结合CNN与Qlearning算法深度强化学习DRL的融合两者结合可突破各自局限深度学习提供强大的特征表示能力,强化学习解决序列决策问题,DRL因此能处理高。
")
1、六和汤是出自太平惠民和剂局方的方剂,具有和中祛湿升清降浊的功效,主治心脾不调霍乱转筋呕吐泄泻等多种病症,妇人胎前产后亦可服用,...

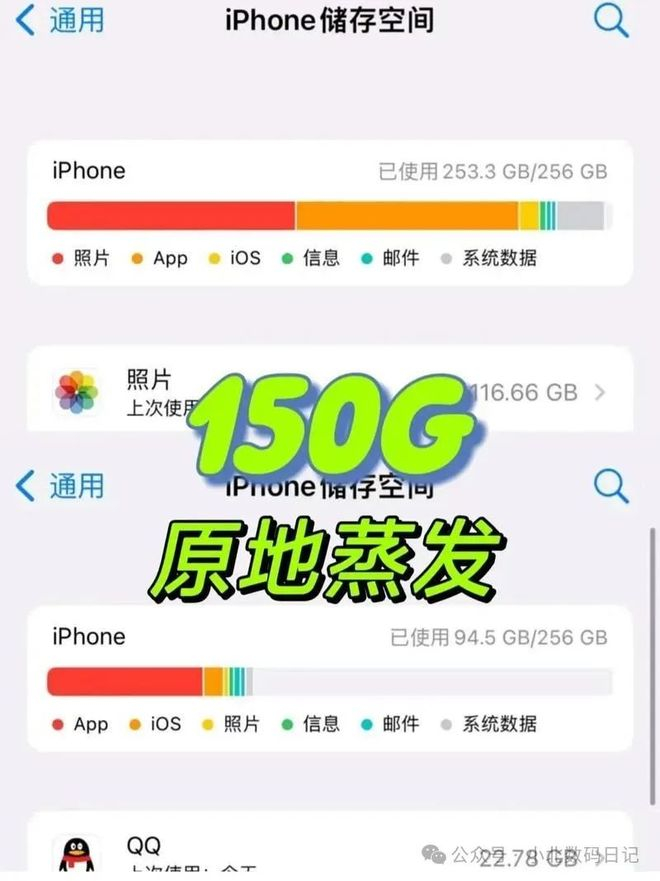
1、完成抹除在抹掉iPhone界面点击继续,等待完成抹除iphone后,就能将苹果手机内容清理干净了。 2、苹果手机清理垃圾可以通...


买房办理商业贷款的利率是在商贷基准利率的基础上浮动得到的,浮动范围通常在05到2个百分点之间具体的商贷基准利率根据贷款期限的不同而...
